Updated: May 7, 2026
In our first dozen replications, we were surprised to find no evidence of p-hacking, and a lot of examples of a problem that didn’t have a name, which we call “Importance Hacking” (as we explored in Part 2).
We wanted to find out if academic psychologists were seeing similar patterns in the field to what we had noticed. Do they perceive p-hacking to still be a common practice in top journals? Were they concerned about Importance Hacking (once we explain clearly what we mean by that phrase), or did they not see it as a serious issue?
To find out, we emailed a survey to more than 2,500 academic psychologists, and promoted the survey on relevant listservs and social media. We received 87 fully completed surveys, and an additional 123 that answered at least some of the substantive questions we asked. These 210 respondents indicated that they were all either experts or experts-in-training in psychology or a related field. There were additional participants who did not meet our screening criteria because they are not experts or experts in training in relevant fields, so their data were excluded from all analyses. For more information about the participants and to access the anonymized data from the study, see the survey demographics appended to Part 1 of this series.
What are Importance Hacking and p-hacking?
Before asking academic psychologists about p-hacking and Importance Hacking, we wanted to be clear about how we were defining both terms. We provided study participants with these two definitions:
p-hacking is taking advantage of choices available to researchers in data collection or data analysis to generate or selectively report results that meet the statistical significance threshold (e.g., p<0.05), when a result wouldn’t otherwise have been statistically significant. p-hacking can be done consciously or unconsciously, but as defined here it is a separate category from fraud (by which we mean falsifying or making up some or all of the data).
Importance Hacking is obscuring or exaggerating the meaning of results to make them appear to have more value so as to get them published, when in reality the results are not worthy of publication.1 A variety of issues could contribute to Importance Hacking including overclaiming, hype, lack of generalizability, or tiny effect sizes that lack real world significance. Importance Hacking can be done consciously or unconsciously, but as defined here it is a separate category from fraud. Unlike with p-hacking, results that are Importance Hacked do replicate, they just don’t have the meaning that is claimed about them.
These definitions highlight that p-hacked results are unlikely to replicate, while Importance-Hacked results (while not meaning what they are described as meaning) do still replicate. Hence, false positives (including p-hacked results) and Importance Hacked results (as defined here) are mutually exclusive categories.
Importance Hacking and p-hacking as strategies for publishing
As we conducted our replications, we realized that there are basically four strategies for getting research published. Producing good research is the most obvious one, but it is also the most difficult to do. The easiest and quickest one is committing fraud (for example by making up data and results), but this is obviously immoral, there are strong norms against it, and serious penalties if one is caught. A common “solution” to the difficulty of producing publishable research without resorting to fraud used to be p-hacking, but as more attention has been paid to the problem of p-hacking, that approach appears to be less commonly used because it is considered less acceptable than in the past. With p-hacking in decline, and researchers still under equally intense pressure to publish, it seems likely that other methods for making work appear more valuable to reviewers would increase. That led us to consider whether other methods exist, at which point we identified Importance Hacking as the missing fourth strategy for publication.
We shared the diagram below with psychology experts in our survey to illustrate these four different mutually exclusive, collectively exhaustive types of published studies:
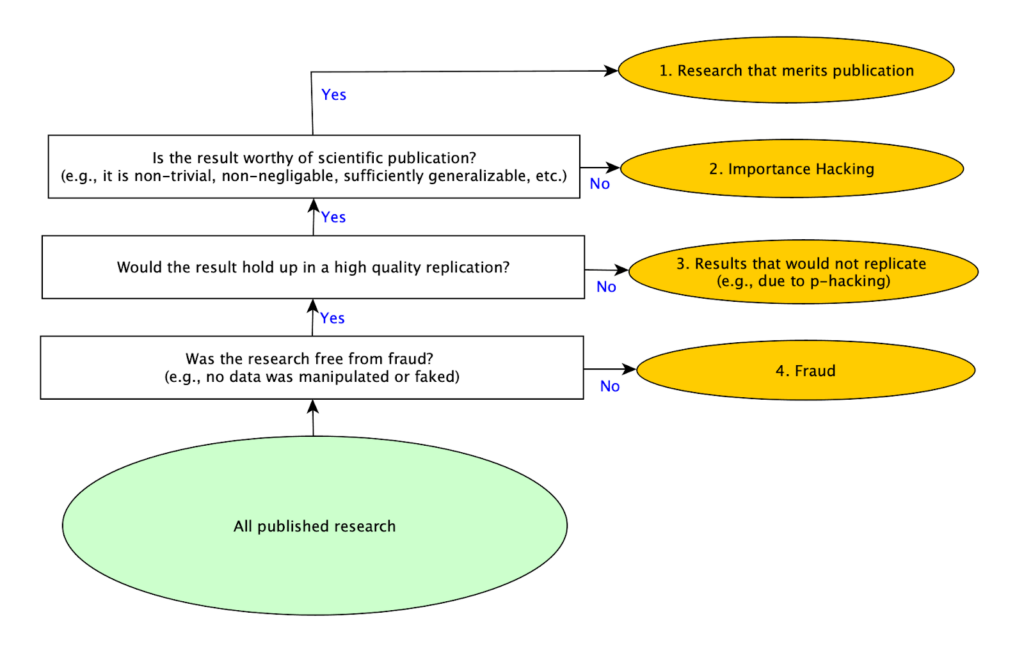
While 10 of the 12 studies we randomly selected replicated and we didn’t find evidence of p-hacking in any of the 12, we saw many studies that were being described (whether consciously or subconsciously) in ways that made the results seem like they meant something different than they actually did. Often, we wouldn’t even realize this until we had carefully rebuilt the study from scratch (as part of our replication efforts). While some attention has been paid to specific problems that fall within this broader category, like overgeneralizing or validity issues, there wasn’t an overall term that encompassed the use of these and related techniques as a strategy to publish papers that would otherwise not be seen as worthy of publication. Much like p-hacking encompasses several more specific techniques, including selectively reporting results after running multiple tests, Importance Hacking is a term for a set of research practices that inflates the value of a research finding by making it seem more novel, clean, or impactful than it really is. For more about the types of Importance Hacking see Spencer Greenberg’s Clearer Thinking article.
Did the experts that we surveyed also see Importance Hacking as a common publication strategy? We were surprised to find out that they did, even though this survey was the first time the term was introduced to them.
Finding 1: Importance Hacking was perceived to be at least as common as p-hacking
We wanted to assess how academic psychologists perceived the literature in the field, so after presenting them with the figure above, we asked them to estimate what percentage of published papers fell into each of the 4 mutually exclusive and collectively exhaustive categories, including papers that present real findings that lack merit for publication due to Importance Hacking (what we now refer to as “Importance-Hacked acceptances”), and papers that are non-replicating for reasons including p-hacking. Here is the question we asked:
Considering only empirical studies that were published in the last 12 months in what you consider to be the top 5 psychology journals: what’s your best guess as to what percentage of them fall into each category?
Please make sure your answers sum to 100%.
1. Real Findings that Merit Publication – studies that report real findings that make a sufficiently valuable contribution to merit publication
2. Real Findings that Lack Merit for Publication due to Importance Hacking – studies that report findings that *would* replicate, but the paper obscures the fact that the findings reported are not worthy of publication
3. Results that would Not Replicate – non-fraudulent studies that report results that wouldn’t replicate (e.g., false positives due to p-hacking, honest mistakes, or bad luck)
4. Fraud – studies that report fraudulent results (e.g., some or all of the data is purposely manipulated or faked)
Participants divided published studies into these four categories, and here is the average percentage assigned to each category:

Academic psychologists believe Importance-Hacked acceptances make up more than a quarter of the papers published in the top 5 journals in the last 12 months. They rated such papers to be as common as non-replicating papers. The non-replicating category includes p-hacking and other causes of non-replication, meaning that the predicted rate of p-hacking is less than 26% of studies. This suggests that people may believe that Importance Hacking is more common than p-hacking.
It is worth noting that the percentage of papers that participants believed would replicate in these questions (the Importance-Hacked acceptances and Real Contribution categories combined), was about 68%, which is 13 percentage points higher than the 55% participants said would replicate in response to the earlier question in this survey asking what percentage of studies published in the top 5 journals in the last 12 months would replicate. It seems possible that this question prompted more thorough reflection because participants’ answers needed to sum to 100%, and the category of replicable findings that lack merit for publication due to Importance Hacking was explicitly introduced, and that difference in context may explain the discrepancy.2
Fraud was suspected to account for almost 6% of articles, which is a small but concerning amount. It’s worth noting that suspecting that nearly 6% of articles are fraudulent is not the same as suspecting that percentage of researchers commit fraud. Since creating fraudulent data is a lot less work than collecting real data, researchers who commit fraud may submit articles more frequently, and also can make more novel claims because the fraudulent data can be used to support whatever conclusions they wish to advance.
After considering the percentage of papers that were problematic in one of these 3 ways, psychologists judged only 41% of papers published in top journals in the last 12 months to be real contributions to the field.
We also asked directly about how serious of a problem psychologists perceived p-hacking and Importance hacking to be in the field.
Finding 2: Importance Hacking was seen as a more severe problem by academic psychologists than p-hacking
We asked two questions about severity, one about p-hacking and one about Importance Hacking:
“How severe of a problem do you think that [p-hacking / Importance Hacking] is in papers published in the last 12 months in what you consider to be the top 5 psychology journals?”
The response scale for these questions ranged from “Not at all” (coded as 0) to “Extremely severe” (coded as 4). The chart below compares the mean response for the two questions:

For recently-published studies in top journals, Importance Hacking was seen by academic psychologists as a more serious problem than p-hacking.
This further underscores that the next frontier in improving psychology research may be Importance Hacking.
Finding 3: Exaggerated claims are a top reason psychology experts say they would reject papers
We also asked psychologists to check boxes next to possible reasons that they would reject papers if they were a reviewer. Of the 7 reasons for rejecting a paper that participants could check, most people checked 3 (35%) or 4 (32%) of them.
The table below shows which reasons were checked most to least frequently by participants:
| Suppose you are a reviewer on a paper – which of these (if any) would you take as grounds for rejecting the paper (if the submitter can’t or won’t correct them)? | % of People Checked | Number of times checked |
|---|---|---|
| The paper makes exaggerated claims that go beyond what was demonstrated by the actual findings | 85.9% | 85 |
| The methodology section lacks sufficient detail to replicate the study | 85.9% | 85 |
| The main analysis was pre-registered but the authors did not stick to the pre-registration plan for the main analysis and did not acknowledge this deviation | 73.7% | 73 |
| The sample size for an experiment with two groups is n=30 per group (i.e., n=60 in total), which is underpowered for the effect size reported | 58.6% | 58 |
| The paper does not report the Simplest Valid Analysis | 18.2% | 18 |
| The analysis used for the main result was not pre-registered | 14.1% | 14 |
| The p-value on the main result is p=0.04 | 12.1% | 12 |
Exaggerated claims (which may be indicative of Importance Hacking) was tied for the most commonly selected reason to reject a paper, with 86% of participants saying that “the paper makes exaggerated claims that go beyond what was demonstrated by the actual findings” was a reason that they would reject a paper as a reviewer.
This shows just how strong a consensus there is that exaggerated claims can be grounds for rejecting a paper, further demonstrating that academic psychologists see Importance Hacking (which is closely linked to exaggerated claims) as a serious issue that needs to be addressed.
It’s a little less clear how this pattern of responses could relate to rates of p-hacking. Of the options in the question, rejecting papers that didn’t follow their pre-registration, rejecting papers with small sample sizes, or rejecting papers with p=0.04 could all potentially be reviewer-driven reasons why p-hacking would be on the decline. Given that respondents say they largely don’t reject papers with p=0.04 on the main result, that is unlikely to be part of the explanation. It’s possible that rejecting papers with small sample sizes, which reduces the potential impacts of removing outliers or other methods for fiddling with the dataset, may be a reviewer-driven reason that fewer papers with p-hacking are being published. Although a large number of respondents said they would reject a paper with undisclosed deviations from its preregistration, it’s not clear how often this problem comes to the attention of reviewers for most journals, since comparing the paper and the preregistration is not a standard part of a reviewer’s workflow. Psychological Science added checking for deviations from preregistrations to their editorial process at the beginning of 2025, but this practice isn’t in place at many other journals to our knowledge.
Key Takeaways
Importance Hacking is seen as a common, and serious problem in the psychology literature. Academic psychologists view it as a more severe problem than p-hacking in top journals currently. This perception is consistent with what we found in our first dozen replications, where we noticed Importance Hacking frequently, but found no instances of suspected p-hacking.
Although we don’t know what the rates of p-hacking were in the past, the lower replication rate found in major replication projects looking at prominent earlier findings suggests that it may have been much more common than it is now. It seems plausible that both the widespread awareness of why p-hacking is a problem, and the adoption of pre-registration as a technique for reducing it, may have led the practice to drop dramatically in recent publications in top journals. This could be driven by researchers improving their own practices, by reviewers being more attuned to p-hacking, or a combination of both. This is a reason for optimism that open science reforms are changing research practices, leading to a more robust and rigorous published literature.
If p-hacking is on the decline, and researchers are still held to the same standard for number of publications in top journals, there may be increased incentives to engage in Importance Hacking. It is difficult to do high quality research, so if one of the easy shortcuts to publication is eliminated, people may be pushed to use another workaround. You can think of the challenge of achieving high research quality as analogous to a pipe with multiple leaks. When you patch one hole (e.g. reducing the amount of p-hacking), more water will spray out of the remaining holes (e.g. importance hacking). To really solve the problem, you need to address all of the holes in the pipe. We believe the next biggest hole is Importance Hacking.
Our next article in this series is about a technique that we developed that can be used to help address Importance Hacking called the Simplest Valid Analysis. Watch for Part 4 in our series to learn what academic psychologists think about the Simplest Valid Analysis, and how it can be used to improve published research.
This article is the third in a four-part series. For more of what we learned, check out Part 1 on the Replication Crisis Part 2 on Three Suprises from our Replications, and Part 4 on the “Simplest Valid Analysis”. Demographic information and anonymized data is available in the Appendix to Part 1.
Note: This article was updated on May 7, 2026 to reflect a more refined definition of Importance Hacking.
- Note we now use the term “Importance Hacking” to refer to the broader practice of making real, replicable findings appear more valuable or worthy of publication than they really are. The definition used in the survey is consistent with what we now call “Importance-Hacked acceptances,” to refer to cases where Importance Hacking makes the difference between acceptance and rejection of the paper. ↩︎
- 144 participants answered the earlier question, while 103 participants answered this question much later in the questionnaire. We don’t have reason to think the respondents who continued with the survey would have systematically different responses from those who didn’t, but wanted to note the difference in participants between the two questions. ↩︎
